この記事の目次
固有名詞は正確に五十音ソートできない。
下の画像を見てください。エクセルで歌手名を五十音でソートした結果です。

解析に少々苦労しましたがおそらく私がつけた赤字のインデックスがソートの境目だと思います。
一番最初の安田成美さんには驚きまました。
と書いてもっと驚いたのは安田成美さんは「やすだなるみ」の入力で一発変換で安田成美と変換されたことです。
という事はIMEは安田成美をやすだなるみとひも付けされているという事になります。
MSのIMEにはちゃんと人名の辞書が入っているんです。しかも最近のトレンドなどもクラウドから引っ張ってきます。
しかしその辞書はどうやら五十音順ソートには使われないみたいですね。
自分がキーボードで入力して作成した名簿は正しくソートされる。
ワードのソートは上の結果から推測するに漢字第1文字目を音読みしてソートしているみたいです。
但し、自分で入力した名前データ場合は入力した読みで認識されます。
ネットから引っ張ってきた名簿や画像からOCRで起こした文字には読み仮名のデータが入っていないので音読みが優先されてしまうのです。
上のデータはCDの曲名ファイルから抜き出したデータですからそれぞれの歌手の読み仮名のデータまでは添付されていません。

例えば学生名簿を五十音で並び変えたい時こんな並びで作成したのではこちらの頭の中で音読みに変換して名簿を探すことになります。
まして配布する名簿などは困ってしまいますね。
ちなみにエクセルのソートも全く同じ結果です。
固有名詞をなるべく正確に並び変える方法
例えば上の荒井由実さんですがおそらく「こういゆみ」と認識されているのでしょう。
しかしこれにワードでルビを打ってみましょう。
ネットで荒井由実を検索検索結果の中から荒井由実の漢字を引っ張ってきてルビを打ってみましょう
荒井由実をワードに貼り付けてルビボタンを押してみましょう。ちゃんと「あらいゆみ」となっています。漢字に読みがなデータが添付されていなくても、ワードの人名辞書や、クラウド辞書から判断して
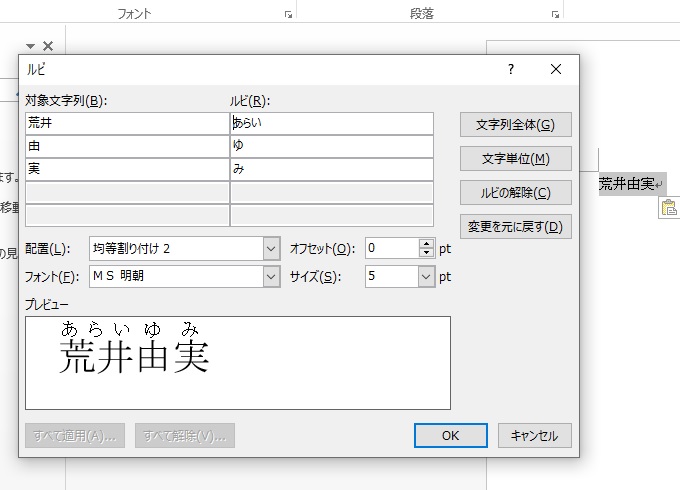 正確な読みになっています。今回はこのルビを利用して固有名詞をなるべく正確に並び変えてみます。
正確な読みになっています。今回はこのルビを利用して固有名詞をなるべく正確に並び変えてみます。
その前に
並び変えはあくまでワード上で行いますのでエクセルのデータを並び変える場合は並び変えたい列をコピーしてワードに貼り付けます。
貼り付けはAの「テキストのみ保持」で貼り付けましょう。
1、ワードの辞書を確認する。
ワードの辞書がクラウドに繋がっているか確認します。
手順は ウインドウズマークから歯車の設定を開いてください。
時刻と言語を選んだら左の方の言語をクリック優先する言語の日本語をクリックします。
日本語をクリックしたらオプションを選びます。
左下のキーボードの追加 から Microsoft IMEをクリックオプションを選びます。
 」
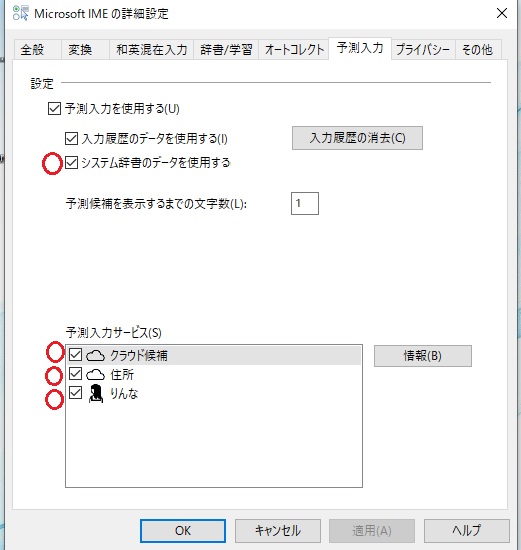
」IMEの詳細設定の下の赤丸にチエックが入っていることを確認してください。良ければOKで閉じます。
2、ルビを抽出する
次の作業は15個づつしかできないので300個ある場合は20回の作業が必要になります。
まずワードの文字列先頭から15個選択します。数は読まなくても少し多めに選択すると時間が省けます。どうせいくら選択しても
15個までしか処理されませんから。その後上のルビボタンを押してください。
画像をクリックで拡大
下の窓が開きますのでそのままOKしてください。
画像をクリックで拡大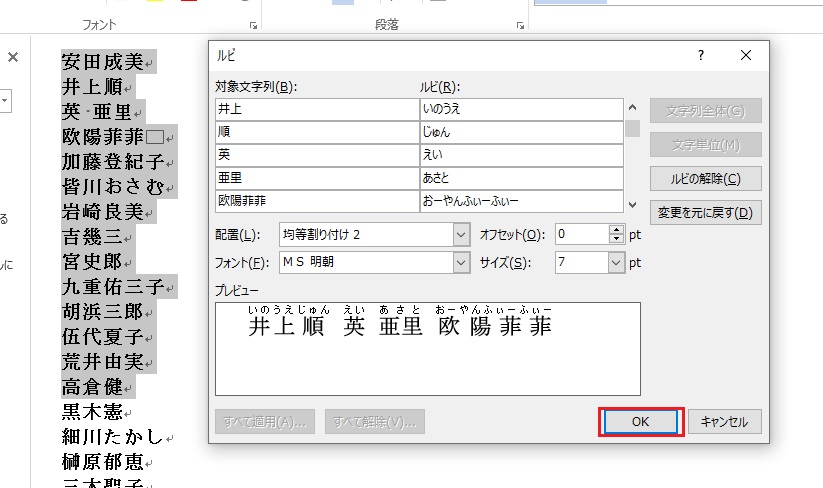
そのままOKすると、下のようにソースがたくさん出てきます。構わずに次の15個に同じことをしてください。
画像をクリックで拡大
全ての処理が終わったら選択からすべて選択してそれから切り取ってください
画像をクリックで拡大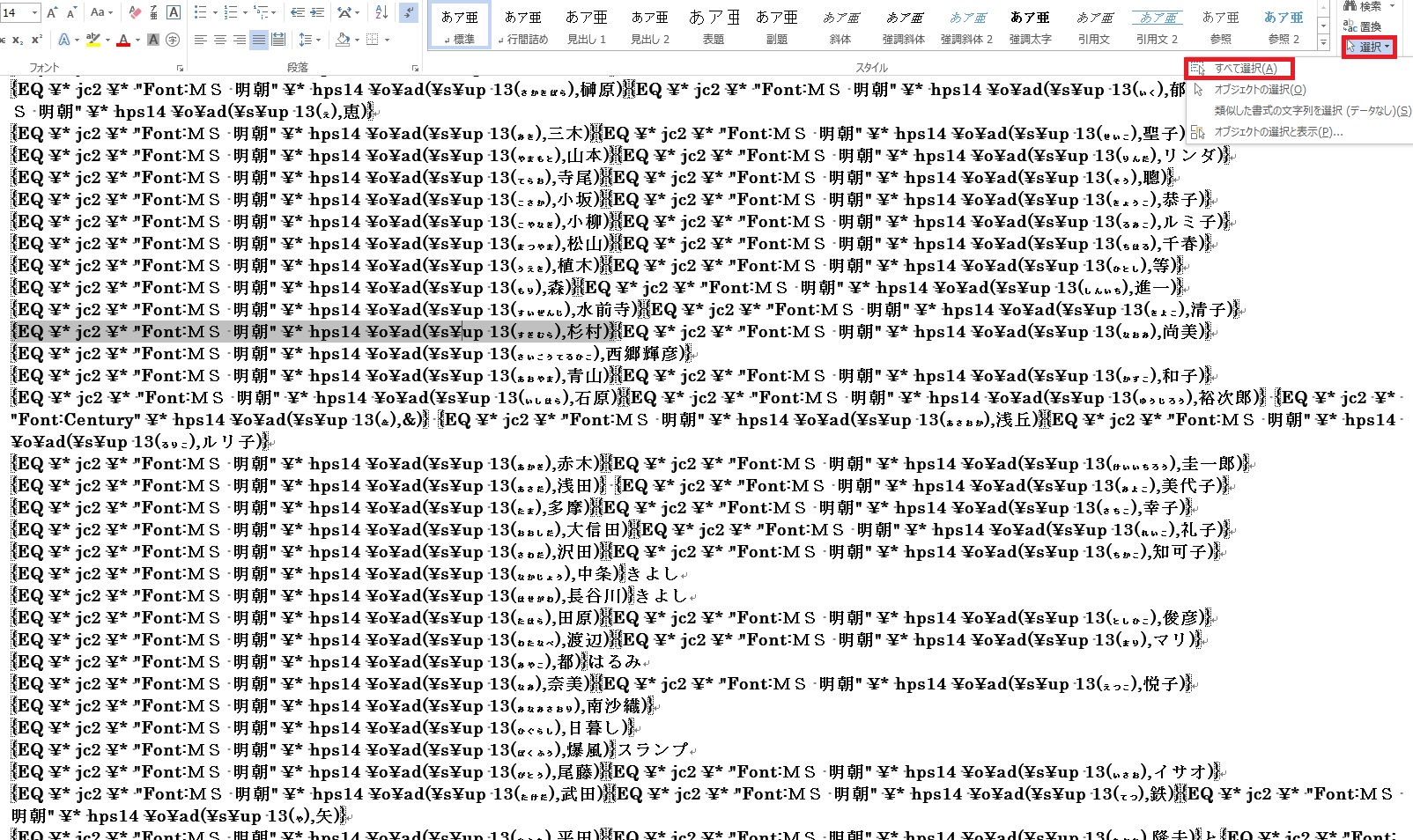
切り取ったらそのままの状態で右クリックでその場所に貼り付けます。
オプションはテキストのみ保持で貼り付けてください。
画像をクリックで拡大

貼り付けると下のように漢字と()の中に読みが書かたリストが出てきます。
画像をクリックで拡大
リストが出たら、茂木の置換をクリックしてウインドウを開きます。検索する文字に「( 」置換後の文字に読点「、」を入れすべて置換します。もし、置換できなければ「(」と「、」はリストの方からコピーして貼り付けてください。
画像をクリックで拡大
同じように今度は検索する文字列だけを「)」に変えて変換してください。
画像をクリックで拡大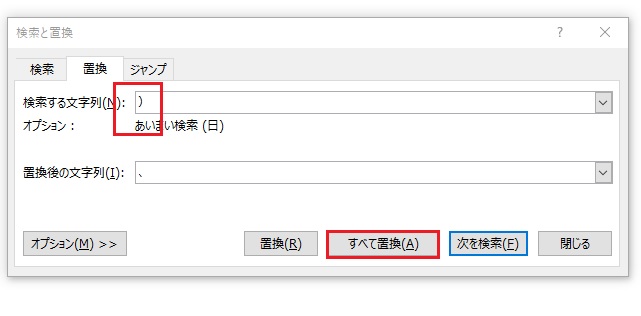
すると下の様なリストになります。これをすべて選択してコピーしエクセルに貼り付けます。
画像をクリックで拡大
エクセルのA1に「貼り付け先の書式に合わせる」で貼り付けます。
画像をクリックで拡大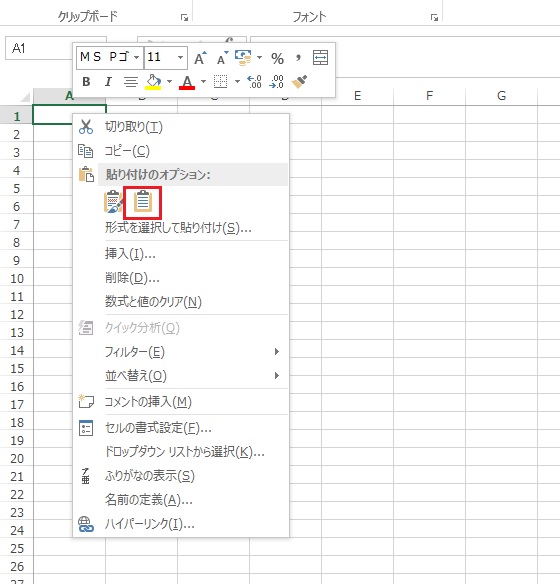
エクセルのA列にペーストされます。
画像をクリックで拡大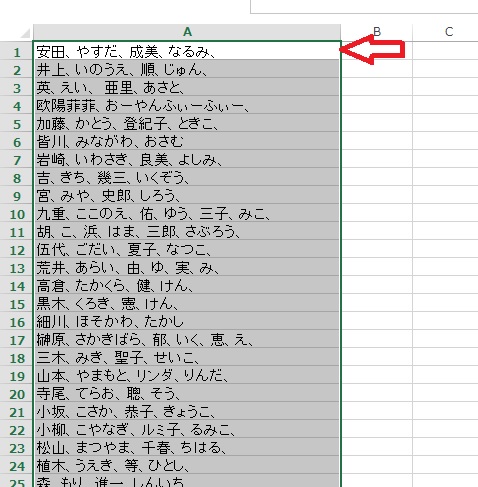
データタブの区切り位置クリックしウインドウが出たら下の画像の赤□にチエックが入っていたら次へをクリック。
画像をクリックで拡大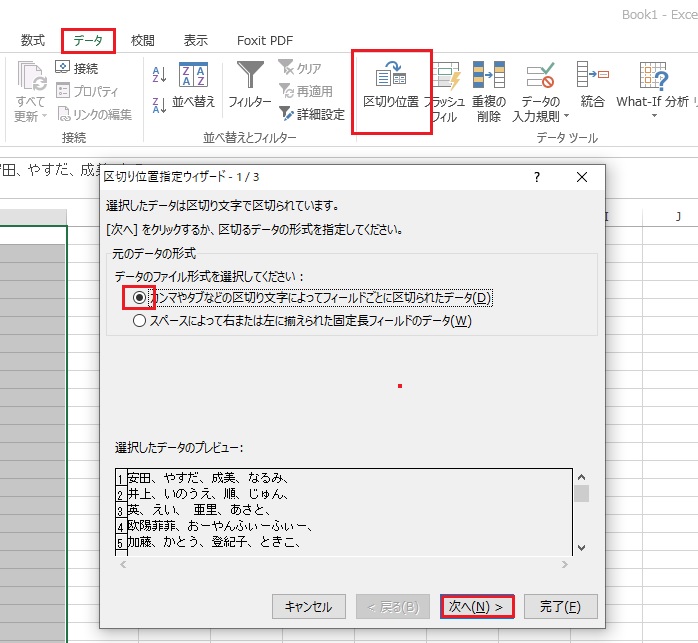
区切り文字をその他にチェックし横の窓には読点「、」を入れます。当店を入れても下の画像のようにひらがなと漢字の間が線で区切られなかったら、読点「、」を貼り付けたリストの中からコピーして貼り付けます。※キーボードからの入力だと微妙に受け付けない時があります。
画像をクリックで拡大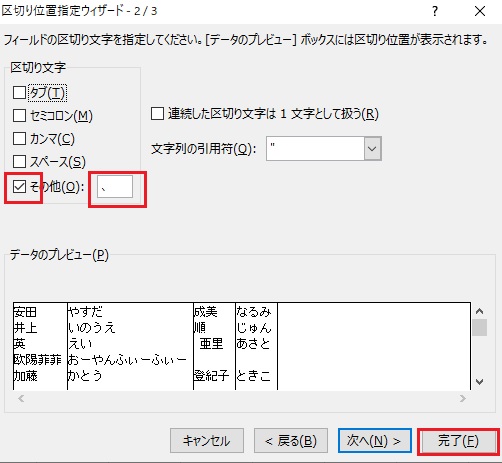
下のように列にひらがなと漢字が分かれたらB列の苗字のひらがなの列を選択し昇順に並び変えます。
画像をクリックで拡大
もちろん選択範囲を拡張するにチェックを入れたまま並び変えてください。
画像をクリックで拡大
下の画像のようにおhぼ正確に五十音順に並びます。
画像をクリックで拡大
その後ひらがなの列は全て削除します。
画像をクリックで拡大
ルビの関係で3つ分割された名前もありますが気にせず進みます。まず、D1に=A1&B1と入力して最後の行までフィルします。
画像をクリックで拡大
D列に2分割は正しく合体して入ります。次に3分割を合体させるためにE1に =D1&C1と入力して最後までフィルします。
画像をクリックで拡大
E列にフルネームが五十音順に並んで入っています。
画像をクリックで拡大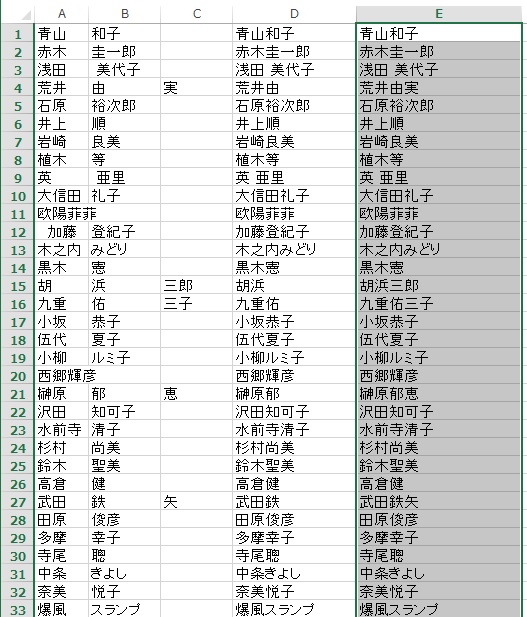
解説
結局ワードの名前辞書を使ってソートしエクセルでひらがなと漢字を分離するわけですがもし名前に関連付随したデータが(年齢や住所など)あった場合はE列以降に
ペーストしておいて後から要らない列を削除して完成させてください。
また特殊な読み方やあまり多くない読みの名前の時は確認しないと音読みで順番が決定している時があります。
今回も「英 亜里」の苗字が「はなふさ」ではなく「えい」と認識しています。また吉幾三さんも「きちいくぞう」になっています。
しかし単純なソートよりはずい分正確になったと思います。
いずれにしても最終確認は人間がしなければなりませんね。